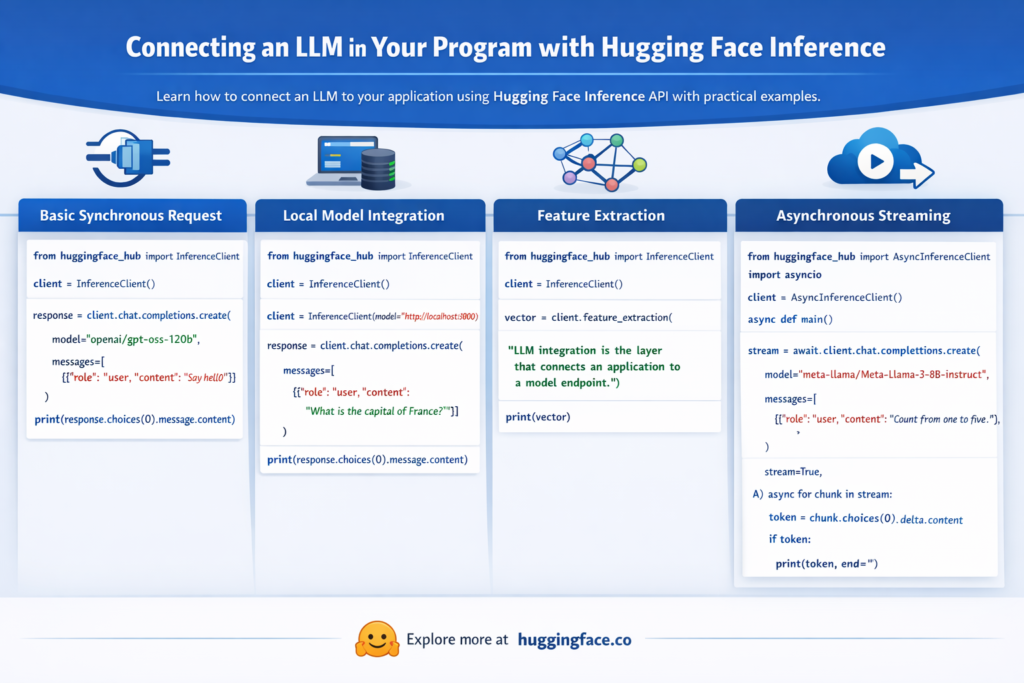
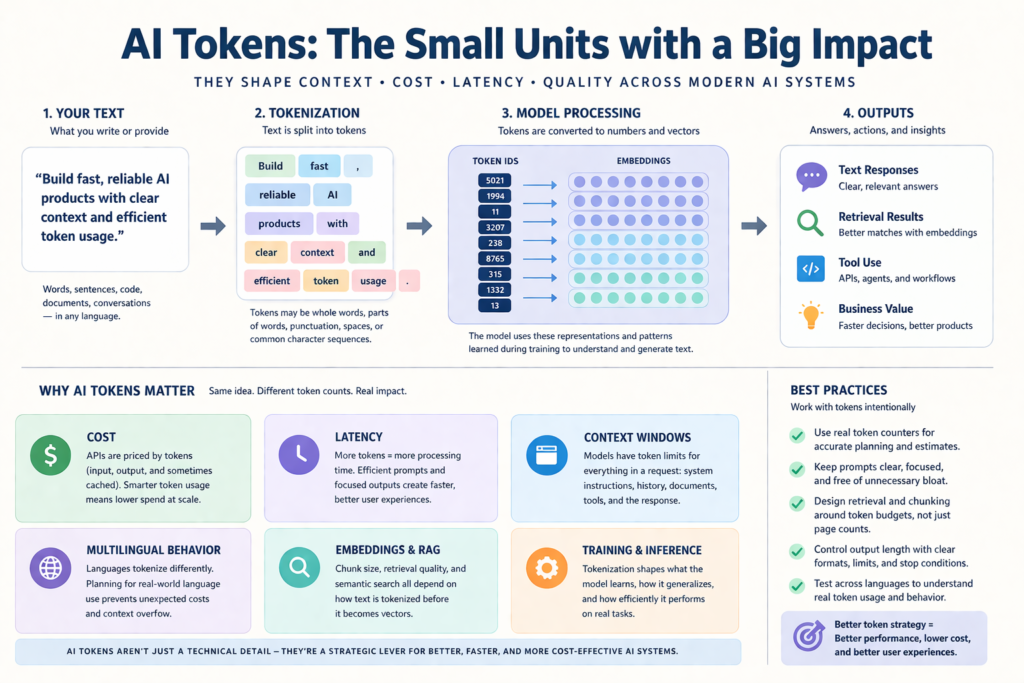
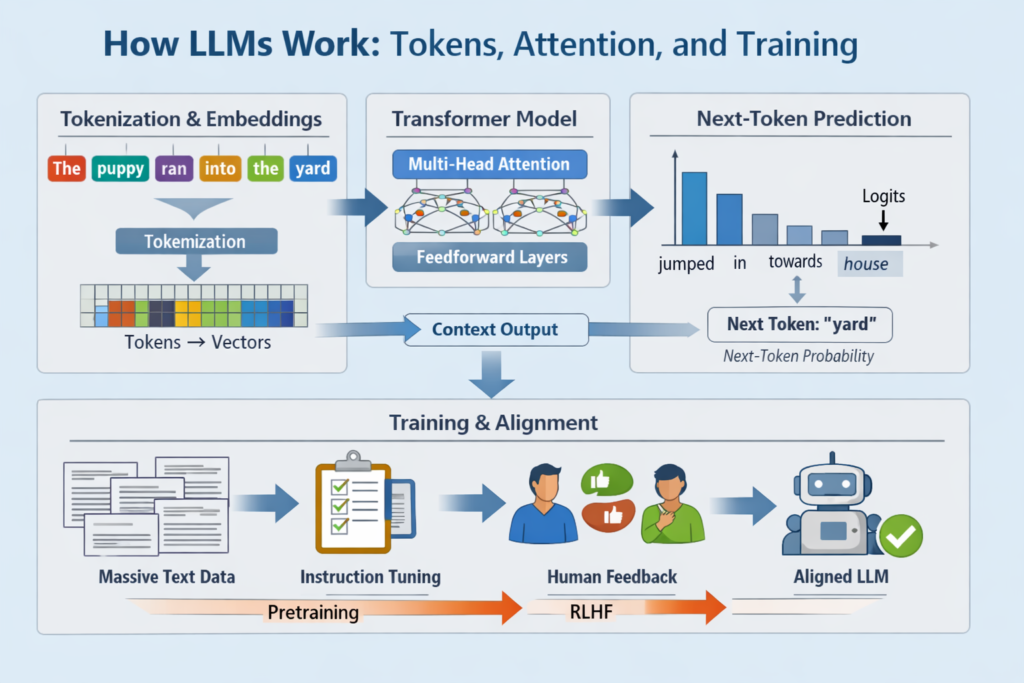
The Claude Code source leak was not a model-weights disaster. It was a revealing look at how real AI products work in production. For business leaders, the most important lessons are about permissions, telemetry, retention, governance, cost control, and operational maturity.
Claude Code Leak: 7 Critical Lessons for Business